So I had a brainwave the other day while out running. There is a particular type of application for generative music that I want to implement that involves leveraging a LAMP style stack in order to serve up a daily dose of music to the url mindfulmusic.today. I’ve got a bit of time on my hands at the moment, so I figure that I can structure a project and learn a bunch about some new technologies that I’ve been wanting to check out. The brainwave came after listening to a guided meditation by the zen master Henry Shukman who was relaying the following koan
Not Knowing is Most Intimate
Dizang asked Foyan, “Where are you going from here?”
Fayan said, “I’m on pilgrimage.”
“What sort of thing is pilgrimage?”
“I don’t know.”
“Not knowing is most intimate.”
Fayan suddenly had a great awakening.
Anyway, in light of the koan and upon pondering a way to approach the project that I had in mind, I figured it might be interesting to collect some of my approach together into a series of blog posts entitled not knowing… Basically, the whole idea with approaching it in this way is to try and develop a bit more of an understanding about some key technologies and practices that I’m interested in exploring. The idea of not knowing what I am doing is quite familiar as a composer, and also more recently as a software developer, so hopefully I will be able to illuminate my ignorance brightly.
I was messing around with a python exercise this morning on hackerrank which
required implementing a few simple data structures and classes. There was
nothing massively complicated about the exercise. The first part involved
implementing a Multiset class, which I did as follows:
class Multiset:
def __init__(self, values=[]):
self.values = values
def add(self, val):
# adds one occurrence of val to the multiset
self.values.append(val)
def remove(self, val):
# removes on occurrence of val from the multiset, if any
if val in self.values:
self.values.remove(val)
def __contains__(self, val):
# returns True when val is in the multiset, else return False
found = False # set initial result
self.values.sort()
for value in self.values: # search
if val == value:
found = True
break
return found
def __len__(self):
# returns number of elements in the multiset
length = len(self.values)
return length
Logically, this seems to cover it and the initial tests pass. As soon as there is a timeout limit set for the test suite though and we try to process a large set of numbers, we run into trouble. So I thought I’d look into it a bit and figure out some of the ways that I could improve the code speed. There are a couple of well worn adages about optimization such as the best is the enemy of the good (Voltaire) or premature optimization is the root of all evil (D. Knuth), so I have dutifully avoided attempting to optimize much in many of my programs up until now. That’s what makes it such a good candidate for the not knowing series!
So, intuitively it’s pretty easy to understand where some of the issues with
this problem are going to arise. We’re trying to create a class that handles a
large set of data. If we’re going to want to get anything reasonable done at
all, we’re going to want make sure that the data is sorted. The class is simple
enough, it just contains a simple list container and a bunch of methods.
The sort is really important for the contains function, but really we are going
to want to do the sorting before we even call that member function. Ideally the
list would be sorted when the object is initialized and when a new member is
added.
Oh yeah, by the way, you usually want to back up any intuitions with some sort of measurements that give you useful data. For this purpose, I discovered a couple of useful little python tools to use on our test program. I’m not going to go to the trouble of importing a unit test framework here, for our purposes it should be enough to simply mock up some data to try out the functions.
So where should we sort? Well, above I’m electing to sort in one place when we
call the Multiset.__contains__. Sort is an expensive operation, so we don’t
want to be calling it willy nilly, let’s just leave it where it is as a single
call before we cycle through the set to find the elements. We know from
complexity theory that an unsorted list runs in O (n) time, whereas sorted will
yield O (log n).
...
if __name__ == '__main__':
import main
# create a set of 10000 random values that remains stable while we test
testvals = []
random.seed(5)
for i in range(1000000):
testvals.append(random.randint(1, 10000))
# create a set of 10 random values to remove
rvals = []
random.seed(4)
for i in range(10):
rvals.append(random.randint(1, 10000))
# create a set of 100 values to search for
findvals = []
random.seed(3)
for i in range(100):
findvals.append(random.randint(1, 10000))
m = Multiset()
# see how long it takes to add 10000 numbers
for v in testvals:
m.add(v)
# see how long it takes to remove a subset of 10
for r in rvals:
m.remove(r)
# see how long it takes to find a subset of 100
result = []
for f in findvals:
result.append(f in m)
The processor in my laptop is snappy enough, so it handles sets with up to 1,000,000 elements pretty easily. As soon as we go 10x beyond this, things start to slow down dramatically. Okay, so there are a couple of useful tools to bring in at this point:
python -m cProfile hrtest.py
Gives us a profile output to the terminal that details what the various
function calls are costing us. cProfile allows us to save this output as a
file with the -o tag and by using the pyprof2calltree module, we can create
a format that can be viewed in KCacheGrind.
pip install pyprof2calltree
...
python -m cProfile -o hrtest.cprof hrtest.py
pyprof2calltree -k -i hrtest.cprof
Viewing this output, we can see that what’s costing us the most in term of
cycles are the calls to Multiset.__contains___
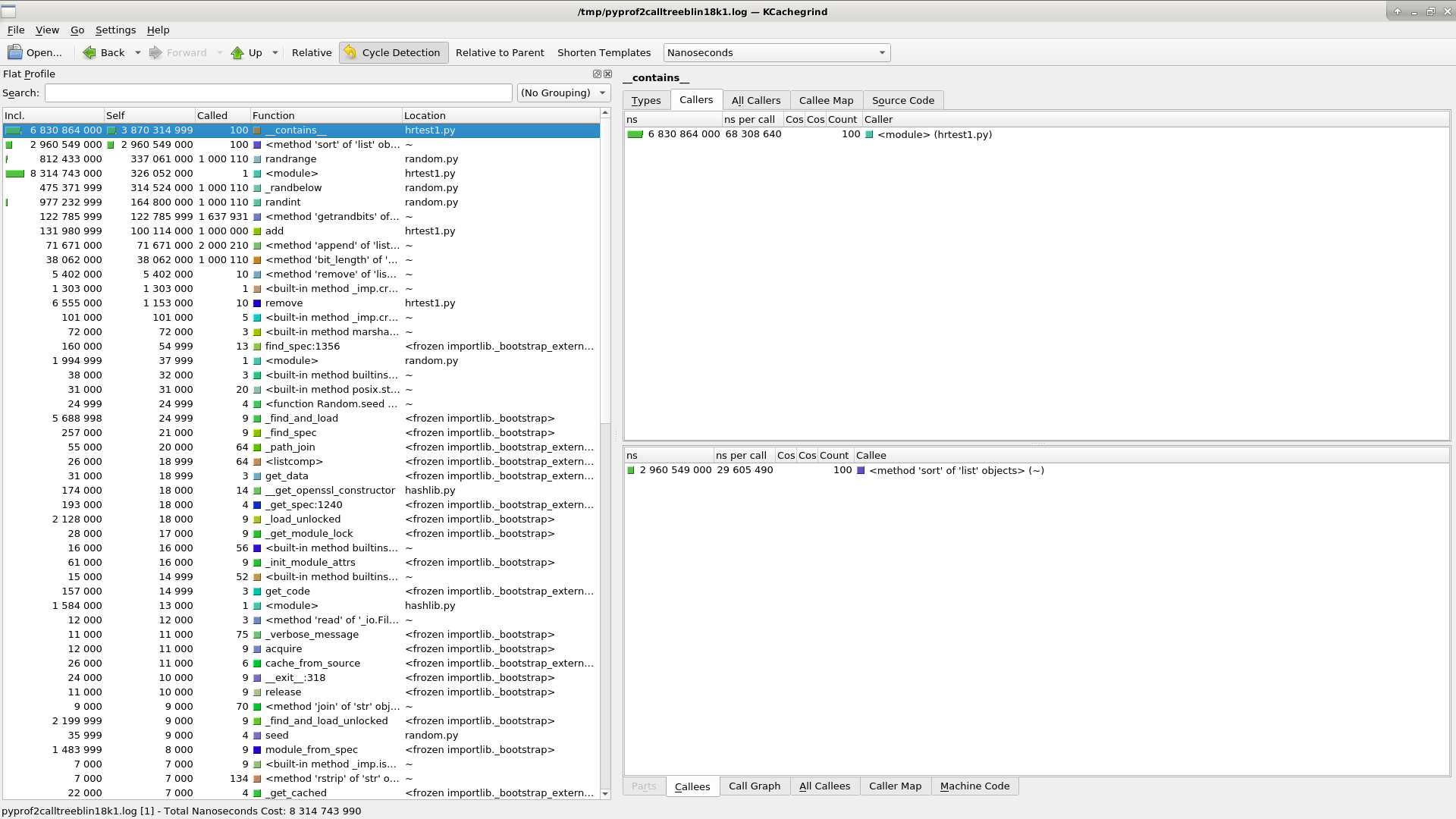
We want to improve the speed of this function, so let’s use the dis module to
dissasemble the bytecode and see how our modifications affect how the program
compiles. Also, let’s use timeit() to see exactly how long the code takes to
execute.
So the first improvement we can try is to use a generator. Generators are a functional programming technique, another thing I know very little about. After mucking about with haskell for an hour this morning, it’s perhaps enough to state for the moment, that the main difference between functional and procedural paradigms is that there is not as much state getting passed around in functional programming.
class MultisetFast:
#... same implementation as Multiset
def __contains__(self, val):
# returns True when val is in the multiset, else return False
self.values.sort()
for value in self.values: # search
if val == value:
yield True
This minor change to our function already gives a noticeable improvement, the actual compilation is unaffected, as evidenced by the disassembly listing, but the speed improves by 3x. The timing is how long it takes to run the contains function over a list of 100000 elements, asserting whether it contains one of 100 possible search items. I’m running the function 100 times, so averaging this means that we require 0.23 and 0.07 respectively to complete the operation.
time pre-optimized: 23.722660299012205
time optimized: 7.319715256002382
Another functional programming trick that we can implement here is to use a list comprehension.
resultm = []
def findvals(queryvals, mset):
for f in queryvals:
resultm.append(f in mset)
def findvalsfast(queryvals, mset):
resultmf = [i for i in queryvals if i in mset]
This causes the compiler to behave differently. And actually, there are no further timing improvements, it’s perhaps even a marginally slower than the standard findvals function where. The one improvement is that the code is more concise, so conceivably contains less room for error.
dis.dis(findvals)
100 0 SETUP_LOOP 26 (to 28)
2 LOAD_FAST 0 (queryvals)
4 GET_ITER
>> 6 FOR_ITER 18 (to 26)
8 STORE_FAST 2 (f)
101 10 LOAD_GLOBAL 0 (resultm)
12 LOAD_METHOD 1 (append)
14 LOAD_FAST 2 (f)
16 LOAD_FAST 1 (mset)
18 COMPARE_OP 6 (in)
20 CALL_METHOD 1
22 POP_TOP
24 JUMP_ABSOLUTE 6
>> 26 POP_BLOCK
>> 28 LOAD_CONST 0 (None)
30 RETURN_VALUE
dis.dis(findvalsfast)
104 0 LOAD_CLOSURE 0 (mset)
2 BUILD_TUPLE 1
4 LOAD_CONST 1 (<code object <listcomp> at 0x7f5f2ecfa150, file "hrtest1.py", line 104>)
6 LOAD_CONST 2 ('findvalsfast.<locals>.<listcomp>')
8 MAKE_FUNCTION 8
10 LOAD_FAST 0 (queryvals)
12 GET_ITER
14 CALL_FUNCTION 1
16 STORE_FAST 2 (resultmf)
18 LOAD_CONST 0 (None)
20 RETURN_VALUE
Disassembly of <code object <listcomp> at 0x7f5f2ecfa150, file "hrtest1.py", line 104>:
104 0 BUILD_LIST 0
2 LOAD_FAST 0 (.0)
>> 4 FOR_ITER 16 (to 22)
6 STORE_FAST 1 (i)
8 LOAD_FAST 1 (i)
10 LOAD_DEREF 0 (mset)
12 COMPARE_OP 6 (in)
14 POP_JUMP_IF_FALSE 4
16 LOAD_FAST 1 (i)
18 LIST_APPEND 2
20 JUMP_ABSOLUTE 4
>> 22 RETURN_VALUE
Just as a final little test, I’m going to increase the size of the sample space that we are searching for values. The reason for doing this is that some aspects of the O complexity may not be fully understood if the sample space is too small. By increasing the number of elements in the searchable list from 100,000 to 1,000,000 and running our test functions again, our improvements reflect a 10x speed up. Again, I don’t fully understand the reason for this, something about the size of the set and the type of algorithm used for sorting/searching does have an effect.
time pre-optimized: 7.531111125004827
time optimized: 0.7105367759941146
Okay, that’s it for now, what are the takeaways? Well, there are a couple of useful tools that we can use to examine our python code more closely and to see where the bottlenecks are happening, functional programming methods such as generators and list comprehensions can be leveraged to give us increases in speed and improve code readability.
Here’s the full code listing:
#!/bin/python3
import math
import os
import re
import sys
import random
class Multiset:
def __init__(self, values=[]):
self.values = values
def add(self, val):
# adds one occurrence of val to the multiset, if any
self.values.append(val)
def remove(self, val):
# removes on occurrence of val from the multiset
if val in self.values:
self.values.remove(val)
def __contains__(self, val):
# returns True when val is in the multiset, else return False
found = False # set initial result
self.values.sort()
for value in self.values: # search
if val == value:
found = True
break
return found
def __len__(self):
# returns number of elements in the multiset
length = len(self.values)
return length
class MultisetFast:
def __init__(self, values=[]):
self.values = values
def add(self, val):
# adds one occurrence of val to the multiset, if any
self.values.append(val)
def remove(self, val):
# removes on occurrence of val from the multiset
if val in self.values:
self.values.remove(val)
def __contains__(self, val):
# returns True when val is in the multiset, else return False
self.values.sort()
for value in self.values: # search
if val == value:
yield True
def __len__(self):
# returns number of elements in the multiset
length = len(self.values)
return length
if __name__ == '__main__':
# create a set of 10000 random values that remains stable while we test
testvals = []
random.seed(5)
for i in range(100000):
testvals.append(random.randint(1, 10000))
# create a set of 10 random values to remove
rvals = []
random.seed(4)
for i in range(10):
rvals.append(random.randint(1, 10000))
# create a set of 100 values to search for
queryvals = []
random.seed(3)
for i in range(100):
queryvals.append(random.randint(1, 10000))
m = Multiset()
mf = MultisetFast()
# see how long it takes to add 10000 numbers
for v in testvals:
m.add(v)
mf.add(v)
# see how long it takes to remove a subset of 10
for r in rvals:
m.remove(r)
# see how long it takes to find a subset of 100
resultm = []
def findvals(queryvals, mset):
for f in queryvals:
resultm.append(f in mset)
def findvalsfast(queryvals, mset):
resultmf = [i for i in queryvals if i in mset]
import dis
random.seed(2)
rint = random.randint(1, 10000)
print("dis.dis(findvals)")
dis.dis(findvals)
print("dis.dis(findvalsfast)")
dis.dis(findvalsfast)
# timeit stuff
import timeit
print("time pre-optimized: ", timeit.timeit(r"""import random
class Multiset:
def __init__(self, values=[]):
self.values = values
def add(self, val):
# adds one occurrence of val to the multiset, if any
self.values.append(val)
def remove(self, val):
# removes on occurrence of val from the multiset
if val in self.values:
self.values.remove(val)
def __contains__(self, val):
# returns True when val is in the multiset, else return False
found = False # set initial result
self.values.sort()
for value in self.values: # search
if val == value:
found = True
break
return found
def __len__(self):
# returns number of elements in the multiset
length = len(self.values)
return length
# create a set of 1000000 random values that remains stable while we test
testvals = []
random.seed(5)
for i in range(1000000):
testvals.append(random.randint(1, 10000))
# create a set of 100 values to search for
queryvals = []
random.seed(3)
for i in range(100):
queryvals.append(random.randint(1, 10000))
m = Multiset()
for v in testvals:
m.add(v)
# see how long it takes to find a subset of 100
resultm = []
for f in queryvals:
resultm.append(f in m)""", number=1))
# timeit stuff
print("time optimized: ", timeit.timeit(r"""
import random
import bisect
class MultisetFast:
def __init__(self, values=[]):
self.values = values
def add(self, val):
# adds one occurrence of val to the multiset, if any
self.values.append(val)
def remove(self, val):
# removes on occurrence of val from the multiset
if val in self.values:
self.values.remove(val)
def __contains__(self, val):
# returns True when val is in the multiset, else return False
values = sorted(self.values())
for value in self.values: # search
if val == value:
yield True
def __len__(self):
# returns number of elements in the multiset
length = len(self.values)
return length
# create a set of 1000000 random values that remains stable while we test
testvals = []
random.seed(5)
for i in range(1000000):
testvals.append(random.randint(1, 10000))
# create a set of 100 values to search for
queryvals = []
random.seed(3)
for i in range(100):
queryvals.append(random.randint(1, 10000))
mf = MultisetFast()
for v in testvals:
mf.add(v)
# see how long it takes to find a subset of 100
resultmf = [i for i in queryvals if i in mf]
""", number=1))